This release adds improvements and bug fixes to v1.25.0. The download links are at the bottom of the page.
We recommend that you back-up important transform files before installing any new release. Please let us know of any problems or issues you encounter with the release.
You can uninstall old releases after you have successfully installed this version.
Windows and Mac
1. There is now a Characters tab in the Right pane. You can use this to see a profile of which types of characters occur in which columns.
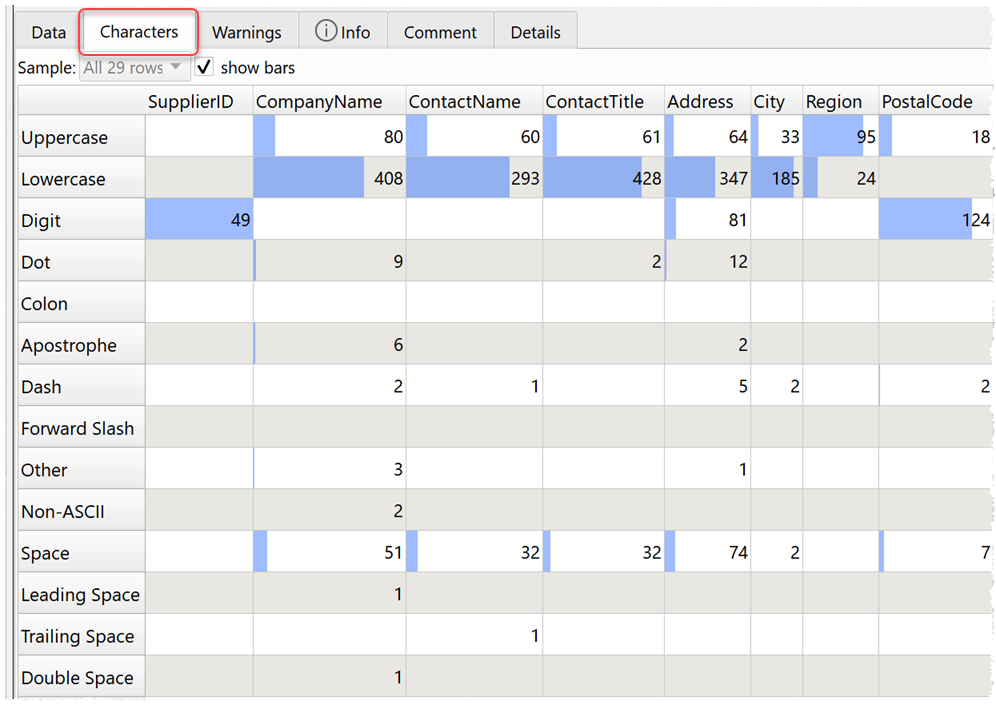
It checks for:
- upper case letters
- lower case letters
- numeric digits
- punctuation
- dots
- commas
- semicolons
- colons
- quotes
- apostrophes
- dashes
- back slashes
- forward slashes
- currencies
- symbols
- other
- non-ASCII characters
- whitespace
- space
- leading spaces
- trailing spaces
- double spaces
- tabs
- carriage returns
- line feeds
Note that some of these categories are non-exclusive. For example: a space might be counted as a space, whitespace and a leading space, and a symbol might also be a non-ASCII character.
Hover over a cell for more details.

You can turn the colored bars off.
And you can restrict it to sampling only a subset of rows for improved speed in large datasets.
The Characters tab can be used in conjunction with the Replace and Whitespace transforms to cleanse a dirty dataset.
2. The Column Values window has been improved. You can display this window by double clicking on a column header or clicking the button.
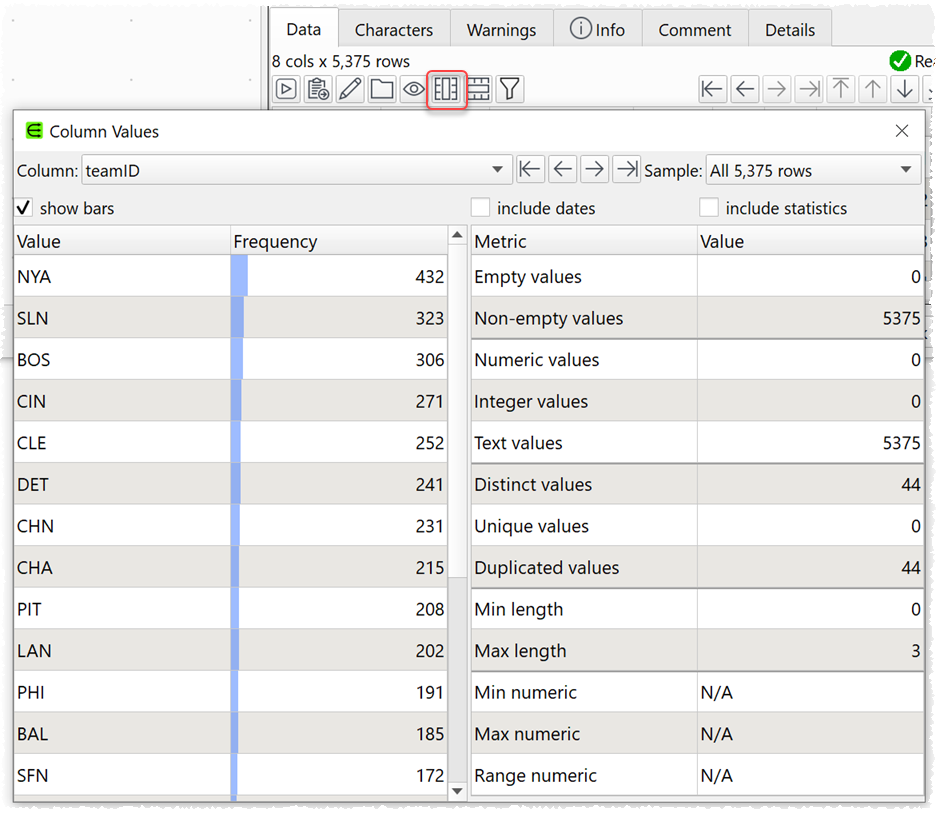
You can now:
- Change the column profiled without closing the window.
- Use sampling to speed up profiling of large datasets.
- See various column metrics, e.g. the number of empty values.
3. The Row Values window has been improved. You can display this window by double clicking on a row header or clicking the button.
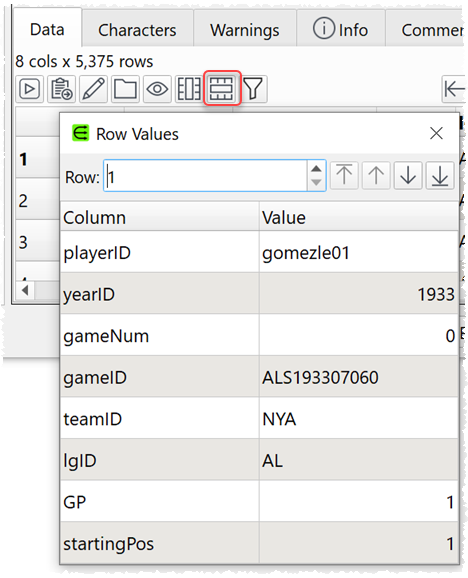
You can now change the row without closing the window.
4. The Dedupe transform now supports ‘fuzzy’ matching. This allows you to remove duplicates that are similar, but not identical.
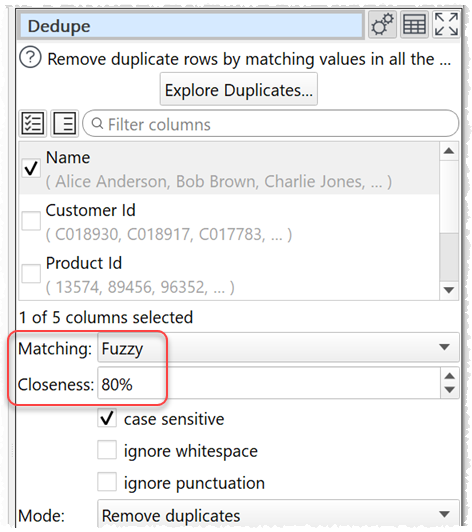
For example, doing a fuzzy match to this value:
100 avenue street, townsville, ohio
Gives:
| Value | Fuzzy match |
|---|---|
| 100 avenue street, townsville, ohio | 100% |
| 100 avnue street, townsville, ohio | 98% |
| 100 avenue street townsville ohio | 95% |
| 100 avenue st., townsville, ohio | 89% |
| 100 avenue st, townsville | 72% |
| 100 av. st., citysville, texas | 52% |
| townsville, ohio | 46% |
| 742 evergreen terrace, springfield, oregon | 36% |
Note that fuzzy matching is significantly slower than exact matching.
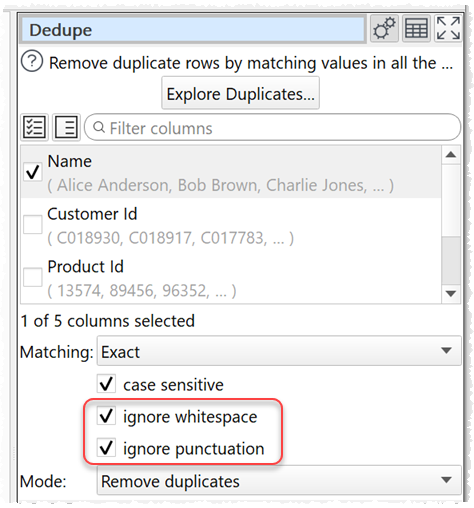
5. The Dedupe transform now has options to ignore whitespace and ignore punctuation. Thanks to Geoff H. for the suggestion.
6. The Dedupe transform now has a Mode option.
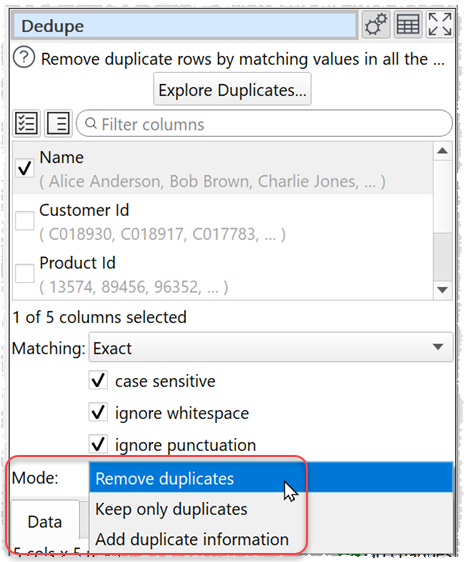
The options are:
- Remove duplicates: The old behaviour.
- Keep only duplicates: Keeps only duplicate rows (the inverse of Remove duplicates).
- Add duplicate information: Adds additional columns relating to duplicates found and re-orders the rows so that duplicates are underneath the row they are a duplicate of. But does not remove rows. This is useful if you want to export the data and then remove rows manually.
7. You can now click the Explore Duplicates… button in the Right pane of the Dedupe transform to see duplicates found with various options. Press the Run button once you have set the options.
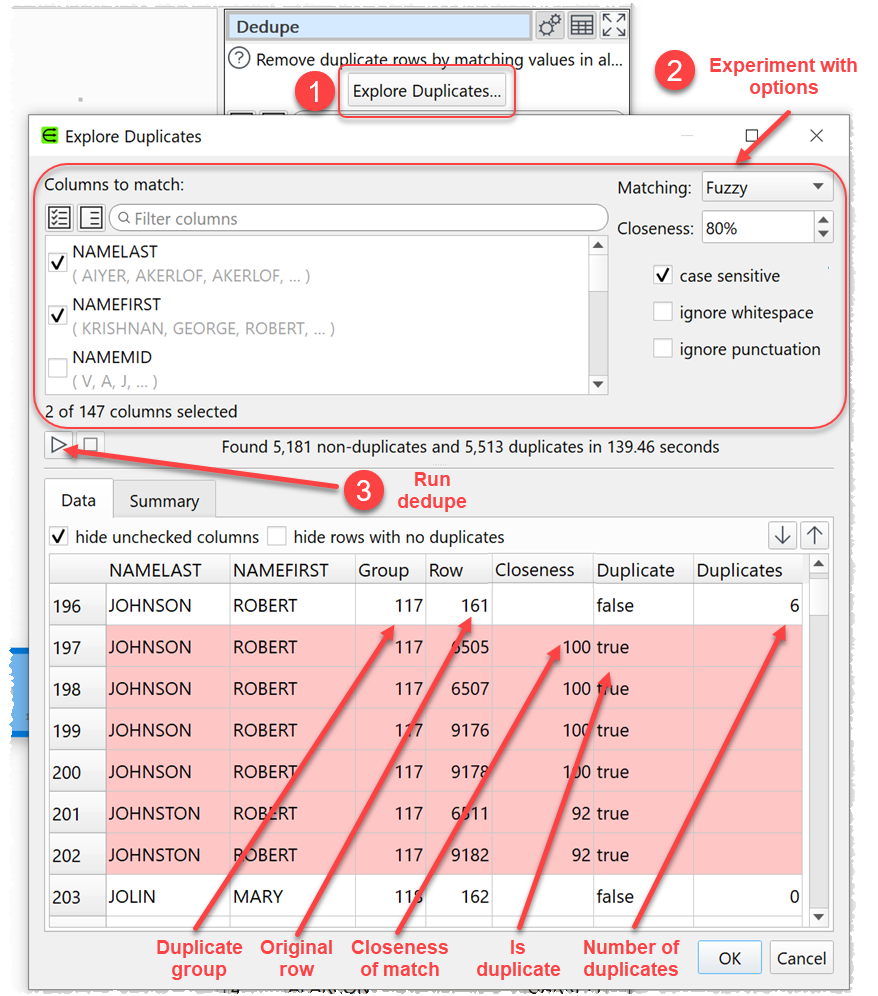
In the Data tab, duplicate rows are colored pink and arranged under the rows they are duplicates of. The following 5 additional columns are added at the end:
- Group: Each row and its duplicates are given a unique group number, starting at 1.
- Row: The number of the row in the input dataset.
- Closeness: How close a match the duplicate is as a percentage. 100% = exact match.
- Duplicate: Set to true if the row is a duplicate and false if not.
- Duplicates: Set to the number of duplicates a non-duplicate has.
A summary of the results is shown in the Summary tab.
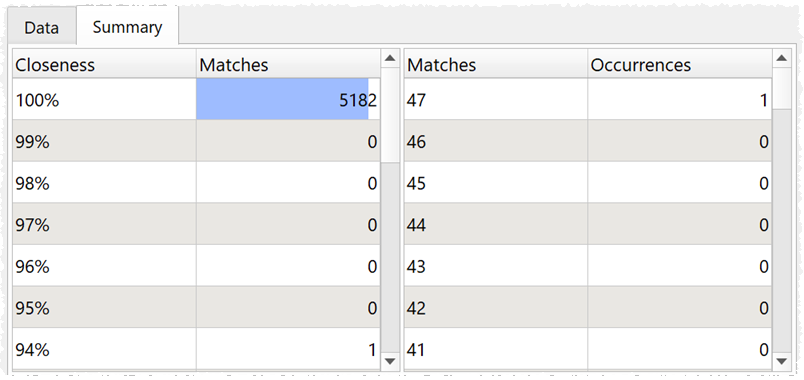
Click OK to keep any change you have made in the settings.
Thanks to Geoff H. for suggestions related to improving de-duplication.
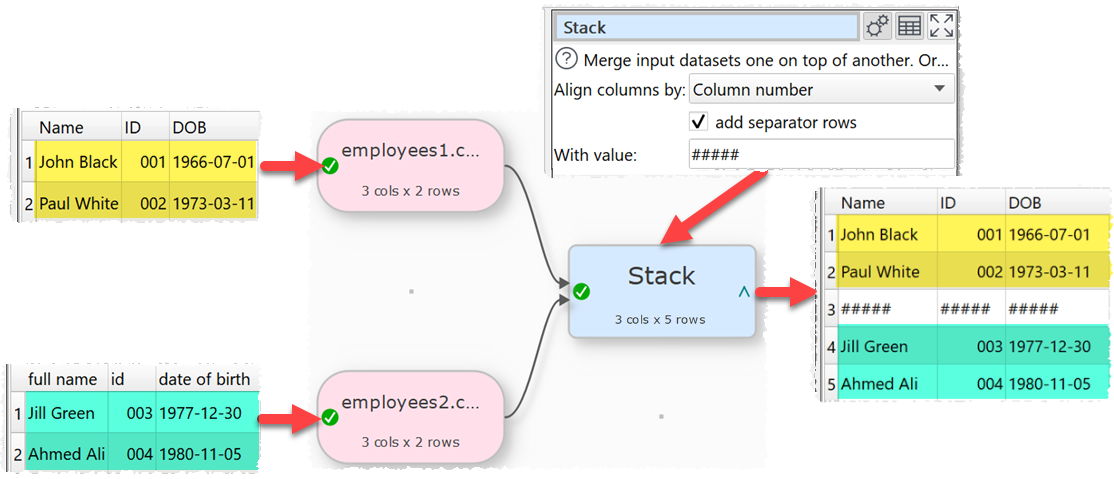
8. In the Stack transform you can now check add separator rows to add separator rows between each input. The With value value is added in each column of the separator rows. Thanks to Chris K. for the suggestion.
9. In the New Rows transform you can now set As to User defined row(s) to add user defined rows. For example to add separator rows.
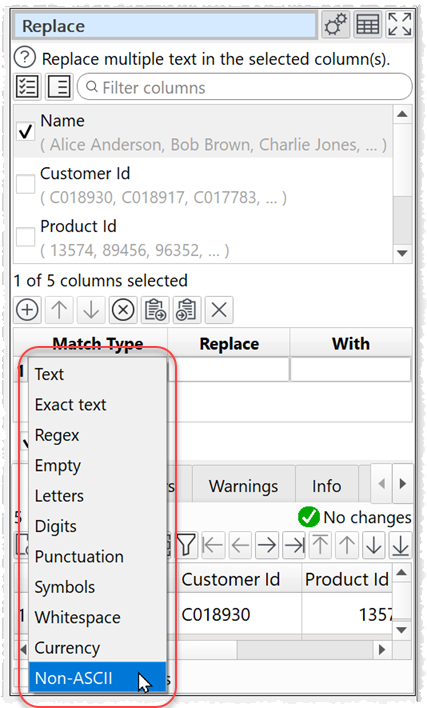
10. The Replace transform now had additional match options for Currency and Non-ASCII.
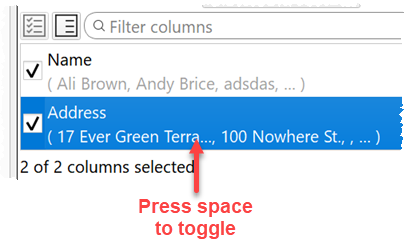
11. You can now toggle a column’s checked/unchecked state using the space bar.
12. The Batch Process window user interface has now been improved so that it can better handle larger numbers of input and output files. Thanks to Marcus A. for reporting this.
13. Memory usage has been improved in batch processing.
14. The default Replace transform is now faster.
15. The Dedupe transform now defaults to having no columns selected.
16. The Mode numeric value output in Summary is now limited to 5 values. Previously the number was unlimited.
17. There was a bug in v1.25.0 where a column set in the Sort transform to sort Ascending could be reset to sort Descending. This is now fixed. Thanks to Frank S. for reporting this.
 Windows Download
Windows Download
 Mac Download
Mac Download