This page summarises some of the improvements we have made to Easy Data Transform in v2.
All Editions
Easy Data Transform now supports schema versioning for inputs. If the input columns differ from expected, you can automatically:
- Insert missing columns (with a default value).
- Re-order out of order columns.
- Add extra columns to the end or ignore them.
Or you can stop with an error.

The new Verify transform allows you to check that a dataset has expected data values.

Currently there are 60 different verification checks you can make:
- All values empty
- At least 1 non-empty value
- Contains
- Don’t allow listed values
- Ends with
- Integer except listed special value(s)
- Is local file
- Is local folder
- Is lower case
- Is sentence case
- Is title case
- Is upper case
- Is valid ASIN
- Is valid EAN13
- Is valid email
- Is valid GTIN
- Is valid IBAN
- Is valid ISBN
- Is valid telephone number
- Is valid UPC-A
- Match column name
- Matches regular expression
- Maximum characters
- Maximum number of columns
- Maximum number of rows
- Maximum value
- Minimum characters
- Minimum number of columns
- Minimum number of rows
- Minimum value
- No blank values
- No carriage returns
- No currency
- No digits
- No double spaces
- No duplicate column names
- No duplicate values
- No empty rows
- No empty values
- No gaps in values
- No leading or trailing whitespace
- No line feeds
- No non-ASCII
- No non-printable
- No punctuation
- No symbols
- No Tab characters
- No whitespace
- Numeric except listed special value(s)
- Only allow listed values
- Require listed values
- Starts with
- Valid date in format
You can set a Severity for each failed rule.
Verification fails are shown, color-coded, in the Right pane data table. Hover over a header or value for information on the rule(s) failed.

You can now Add Folder to input multiple files as a single dataset. This powerful new feature allows you to stack hundreds of files or Excel sheets from a hierarchy of folders, without having to specify the individual files/sheets.
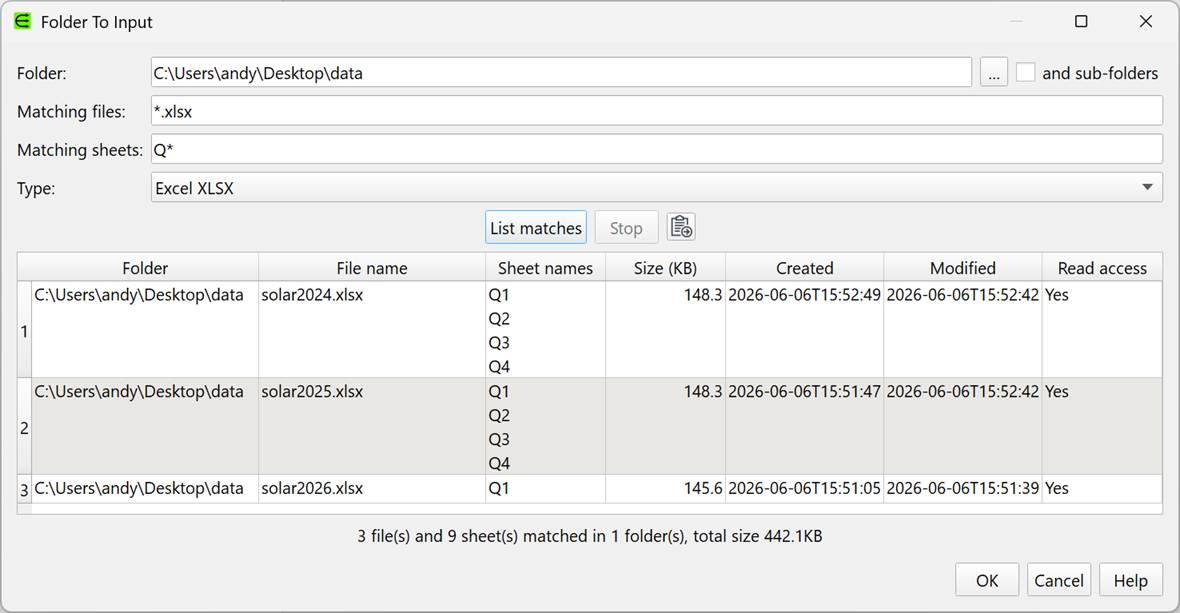
You can use a Schema to deal with differences in column structure between files.
You can now use Edit>Cut, Edit>Copy and Edit>Paste to cut, copy and paste items in the Center pane.
The new UUID transform allows you to add a column of Universally Unique Identifiers (UUIDs).

The new Reshape transform allows you to reshape the values of a dataset into a different number of columns. The new number of rows is calculated automatically.

The new Pseudonym transform allows you to pseudonymise a column of data.

The new Split Name transform allows you to split a column of people’s name into honorifics, first names, middle names, last names and suffixes.

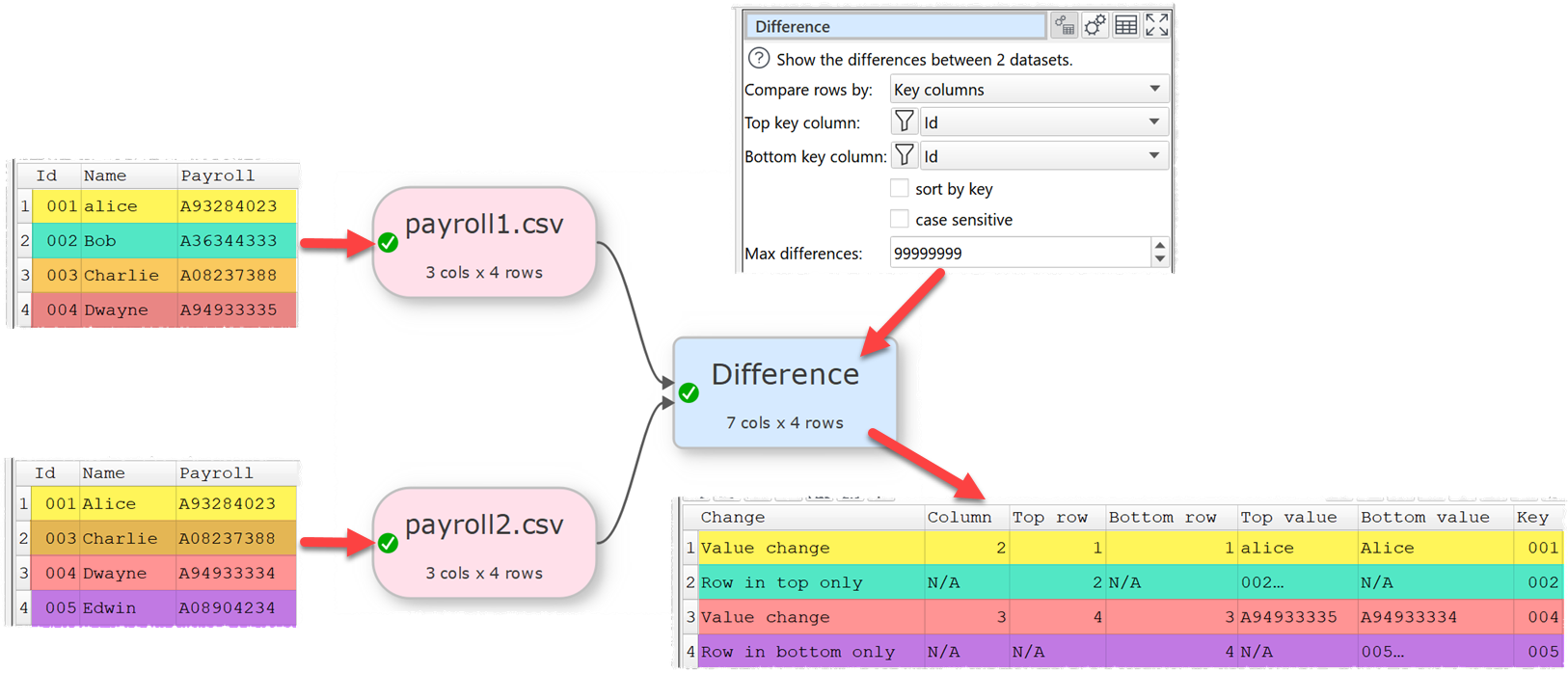
The new Difference transform allows you to output the differences between 2 dataset by Row numbers or Key columns.
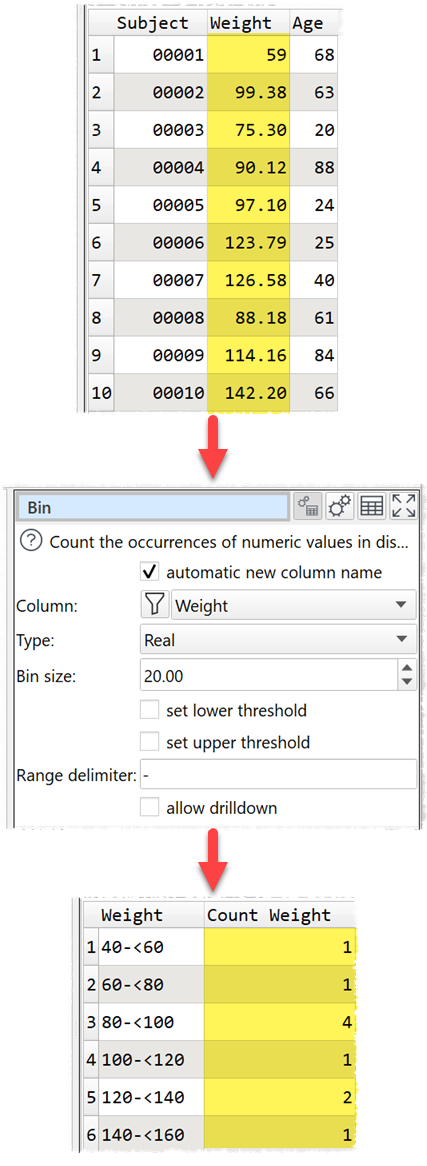
The new Bin transform has been added. This counts the number of integer or real values falling into discrete bins. You can add lower and upper thesholds.
The new List transform has been added. This allows you to perform a wide range of operations on a delimited list of values in a column.
For example deduplicating names in a comma+ampersand delimited list:
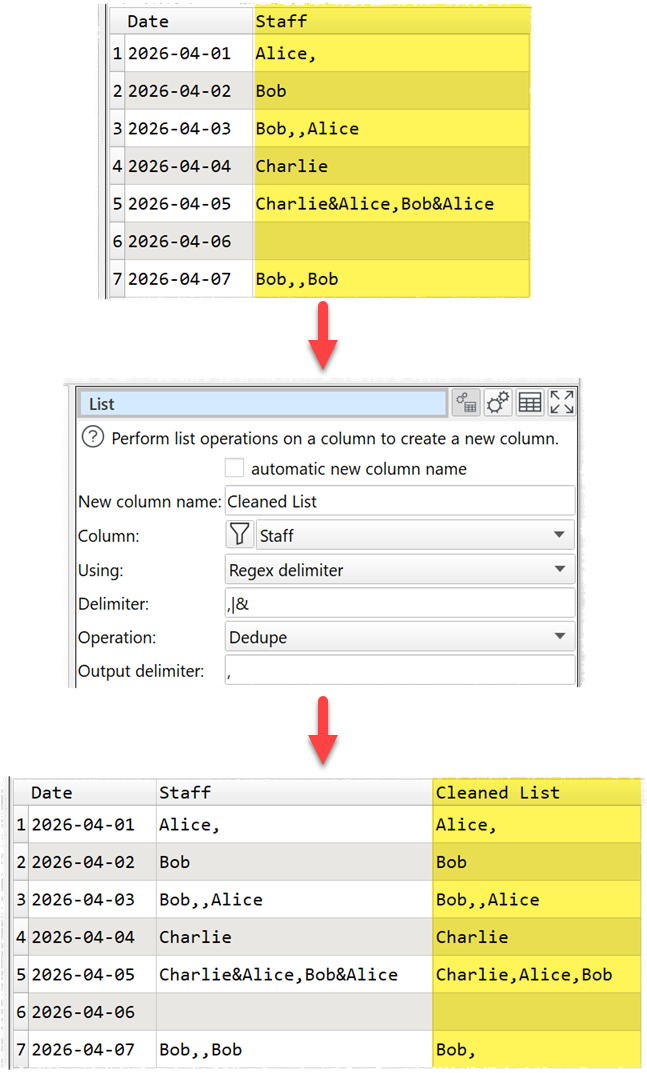
Or summing values in a comma delimited list:
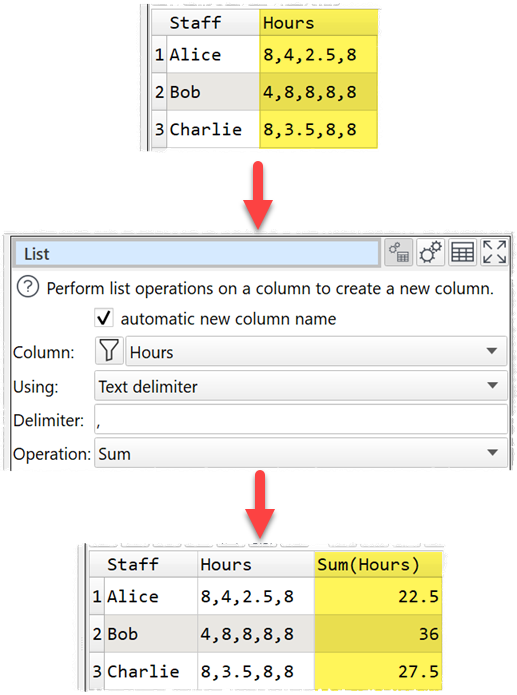
The list operations supported are:
- Average
- Count
- CountDistinct
- Dedupe
- First
- Last
- Maximum
- Median
- Minimum
- Product
- RemoveEmpty
- RemoveEven
- RemoveFirst
- RemoveLast
- RemoveOdd
- ReverseItems
- ReverseOrder
- SortAscending
- SortDescending
- Sum
- Tidy
- Trim
The Pivot transform now supports multiple levels of pivoting. You can set any number of pivot levels.

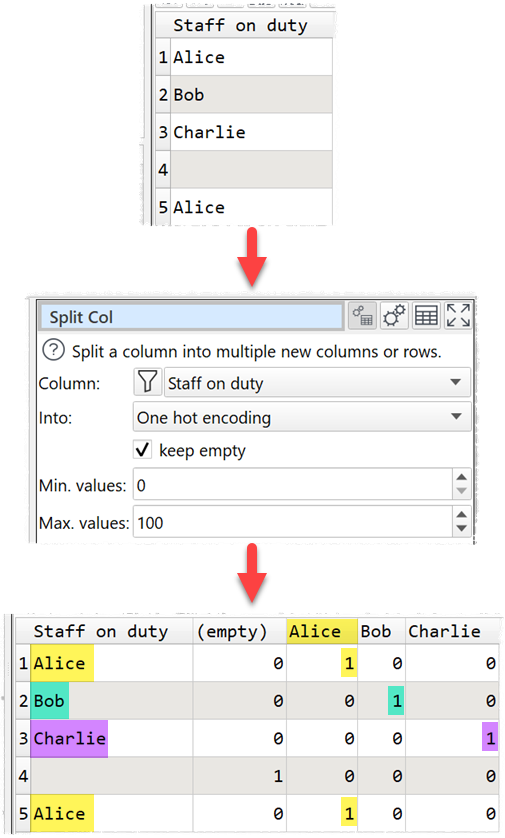
The Split Col transform now has additional Into options:
- Count vectors
- Multi hot encoding
- One hot encoding.
Count vectors creates a column for each split value, with the number of times the value is present in the row. For example, from a list of staff names, you can create a column for each staff member showing how many times they were on duty for each date.
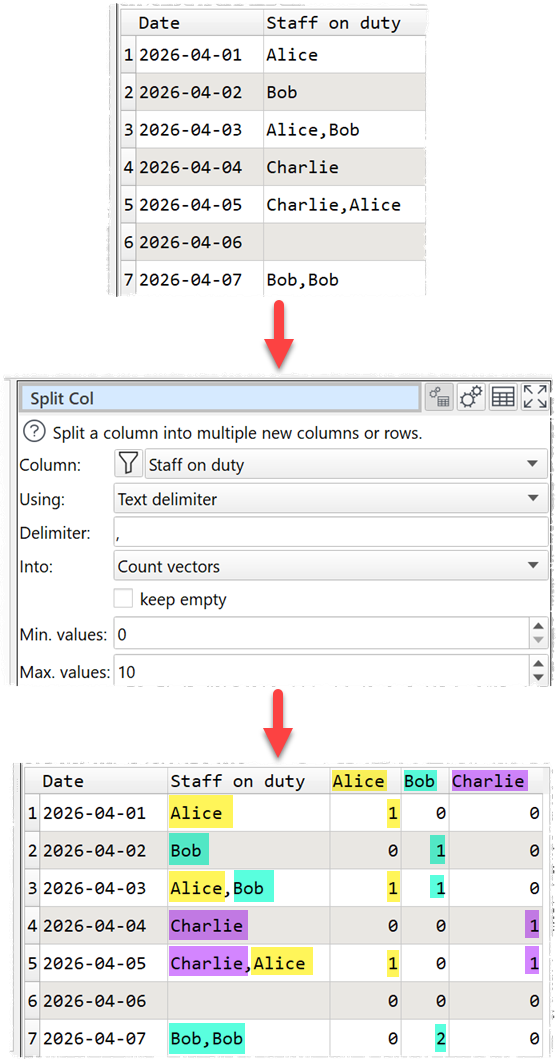
Multi hot encoding is similar to Count vectors, but it uses a 1 or 0 to show if a value is absent or present. Duplicate values are ignored. For example, from a list of staff names, we can create a column for each staff member to show whether they were on duty or not for each date.
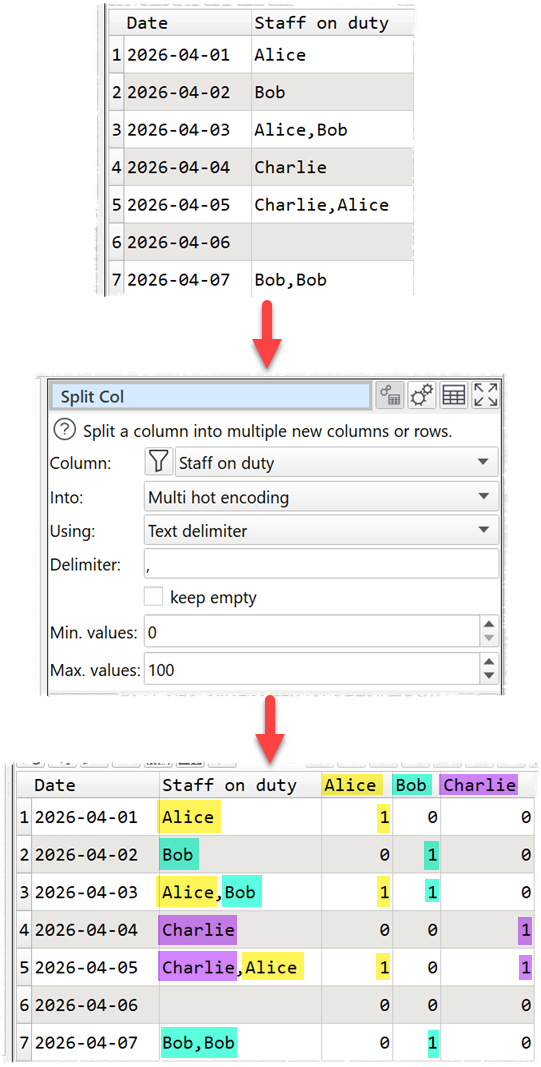
One hot encoding is similar to Multi hot encoding, expect that each row is treated as single value, not as a lsit.
Previously, when you disconnected an item and reconnected it to a different upstream item, all the column related option would be reset. This could be time-consuming to fix. Easy Data Transform will now try to repair broken column references, by setting them to columns that have the same name, in the new upstream item.
For example: In the animation below there are 2 datasets with ‘Weight’ and ‘Age’ columns. Disconnecting from one and connecting to the other causes the columns with the same names to be referenced in the downstream items, even though the columns are in a different order.

You can now easily compare the column structure in 2 or more datasets, by Column name or Column index.


You can now easily compare data values in 2 datasets, by Row numbers or Key columns.


An overview of the differences are shown on the left. You can click or drag this overview to navigate.
You can now select View>Item Summary (or click the new toolbar button) to display a window summarising all the items in the Center pane.

You can now Join 2 datasets by Row number instead of using key columns.

The Matching option in the Lookup transform now has additional options:

This allows you to do transforms like this:

The No match value option in the Lookup transform can now be a column variable.

The Sort transform now has additional options:
- Check intelligent sort to optionally sort dates as dates, and numbers as numbers.

- Check locale aware to use the Locale set in Preferences to determine the sorting order of text.
- Check case sensitive for case sensitive sorting of text.
The Calculate transform can now accept either a column or a single value as the first value for binary operations. Previously the first value had to be a column.

The following operations have been added to the Calculate transform:
- DaysInMonth to calculate the number of days in the month for a date value.
- DaysInYear to calculate the number of days in the year for a date value.
- Occurrences to calculate the number of times 1 piece of text occurs in another piece of text.
- MSecsToTime to convert an integer number of milliseconds since midnight to a 24 hour time.
- TimeToMSecs to convert a 24 hour time into the number of milliseconds since midnight.
- AndBitwise to bitwise AND 2 numbers.
- OrBitwise to bitwise OR 2 numbers.
- XorBitwise to bitwise XOR 2 numbers.
- DateTimeAddMSecs to add milliseconds to an ISO datetime
- DateTimeAddSecs to add seconds to an ISO datetime
- DateTimeAddHours to add hours to an ISO datetime
- DateTimeAddDays to add days to an ISO datetime
- DateTimeAddMonths to add months to an ISO datetime
- DateTimeAddYears to add years to an ISO datetime
- DateTimeToUTC to convert an ISO datetime to UTC (Coordinated Universal Time)
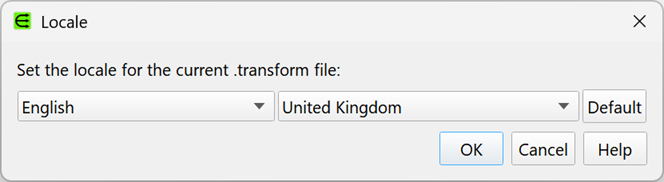
Locale is now set at the document (.transform) level.
You can change the locale of the current .transform by selecting Edit>Locale… from the main menu or clicking the new Locale button in the status bar.
The DateTime Format transform can now change the date format based on input and output locales.

The Num Format transform now has Locale from and Locale to options.

The Random transform can now generate random Date and Text values, in addition to the existing Real and Integer options. This can be very useful for generating synthetic data.


The following additional metrics have been added to the Summary transform:
- Format date: The inferred format for dates in this column.
- Range date: The number of days between the maximum and minimum dates (inclusive).
- Distinct dates: The number of different dates. 01/01/2025 and 1/1/2025 are considered to be the same date for this purpose.
- Missing dates: The number of missing dates between Min date and Max date.
Inputs, transforms and outputs now have smarter defaults.
Null characters (ASCII/Unicode value=0) are now displayed when you click show invisible:

They now are also shown separately in the Characters tab.

And you can insert Nulls into text fields, e.g. to replace them using Replace:

The Find Items window has additional check boxes for:
- ids
- column names
- data values

Added Record separator (0x1E) as an option for Line endings when outputting text files.
You can now check or uncheck columns that match a range of criteria in any transform that allows the selection of multiple columns.

You can also filter columns by name in various transforms.




This should make selecting columns a lot faster for datasets with lots of columns.
When you are outputting in Excel format, you can now check use style template to copy the styling from another Excel sheet.

Styling copied from the template sheet includes:
- column widths
- row heights
- merged cells
- cell borders
- text orientation
- fonts
- colors
Hovering over a connection now highlights the connection and the items at either end. This makes it easier to select connections and to trace flows.

Hovering over a transform button in the Left pane now highlights all transforms of that type in the Center pane. You can use this as a quick way to find transforms of a particular type.

View>Zoom Selected has been added. This allows you to zoom in on any selected items in the Center pane.
You can now toggle the Left and Right pane visbility using View>Left Pane, View>Right Pane or the corresponding buttons on the status bar.

You can now hold down the Ctrl (Windows)/Cmd (Mac) key when adding a new transform or output item to add it to the bottom left of all the current items, rather than to the right of the selected items.

There is now an additional Remove option in the Subtract transform.

The following options have been added to the Unique transform:
- Count unique to count distinct values with no duplicate. E.g. values A,A,B,C has 2 unique values: B,C. All values are treated as text. Empty is counted as a value.
- Count duplicate to count distinct values with duplicates. E.g. values A,A,B,C has 1 duplicate value: A. All values are treated as text. Empty is counted as a value.
- Count distinct to count distinct values. E.g. A,A,B,C has 3 distinct values: A,B,C. All values are treated as text. Empty is counted as a value.
- Count empty to count empty values. Values containing whitespace are not empty.
- Count non-empty to count non-empty values. Values containing whitespace are not empty.
- Set empty sets the value to empty.
There is now an ignore empty values for concat option in the Unique transform.

There is now a case sensitive option in the Unique transform. When this is checked, case is taken account of for Keep unique matching.
The Fill, Unfill and Slide transforms now have a new For option to only fill/unfill when the adjacent cells have the same value in a key column. This only works when filling/unfilling up or down (not left/right).

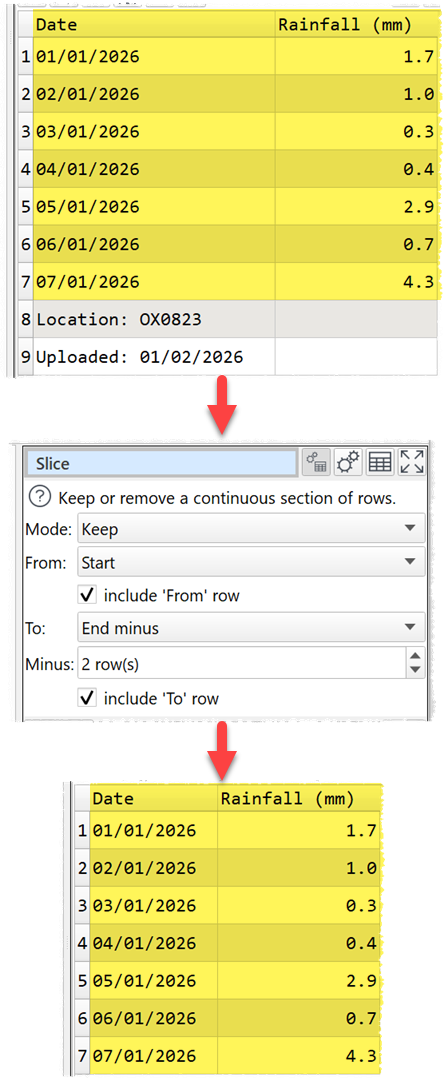
The Slice transform has addition From option Start plus and additional To option End minus. This allows you to start and/or end slices a certain number of rows from the top or bottom of the dataset, even when you don’t know the number of rows in the dataset. For example, you can easily remove the last 2 (footer) rows of a dataset:
We have improved how Easy Data Transform handles real (floating point) numbers, to try to avoid numerical artifacts.

You can now preview the data in an item without selecting that item. Hover the mouse over an item in the Center pane and press the # key to display the Data Preview window.

You can now double click on some cells in the Column Values window to drilldown and see the corresponding rows in the dataset.

Including duplicate values:

And the most or least frequent values:

The following additional metrics have been added to the the Column Values window:
- Format date: The inferred format for dates in this column.
- Range date: The number of days between the maximum and minimum dates (inclusive).
- Distinct dates: The number of different dates. 01/01/2025 and 1/1/2025 are considered to be the same date for this purpose.
- Missing dates: The number of missing dates between Min date and Max date.
The following file name variables have been added:
- {day}
- {month}
- {year}
- {hour}
- {minute}
- {second}
- {computername}
The transforms drop down menu now allows you to show only the most used or most recently used transforms:

Check move Note items with associated items in the General tab of the Preferences window, if you want Note items to be automatically moved when you drag other items that the notes are adjacent to and pointing at.

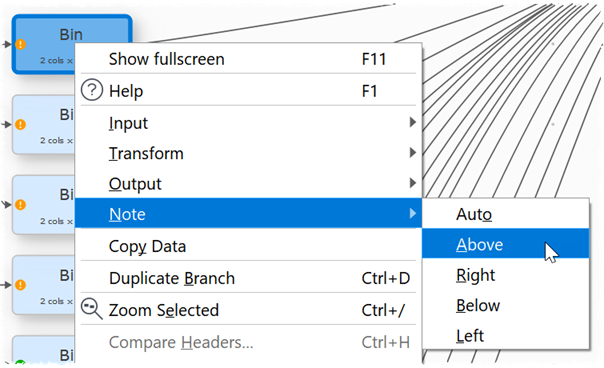
You can now select the position of a new Note item from the right click menu.
If you start typing with a single Note item selected in the Center pane, the text will be appended to the Note Comment field, which will also get focus.
Output to the log pane, from batch processing and from command line processing has been made clearer and more consistent.
Logging during batch processing or command line processing can now be set to the following verbosity levels:
- 1: summary
- 2: normal
- 3: extra
- 4: maximum
The Batch processing window now has a vertical splitter and the option to hide the tips text.
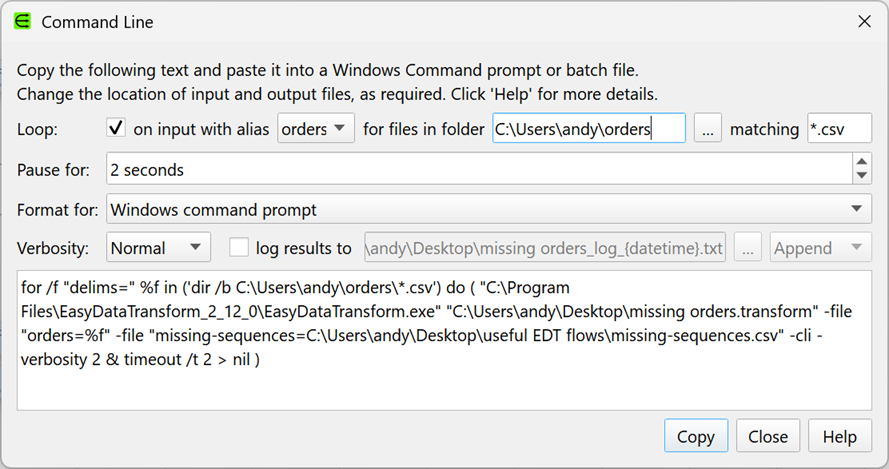
The Command Line window now supports looping.
Previously, when outputting to XML, nodes with children were always output before sibling nodes with children. The original column ordering is now preserved.
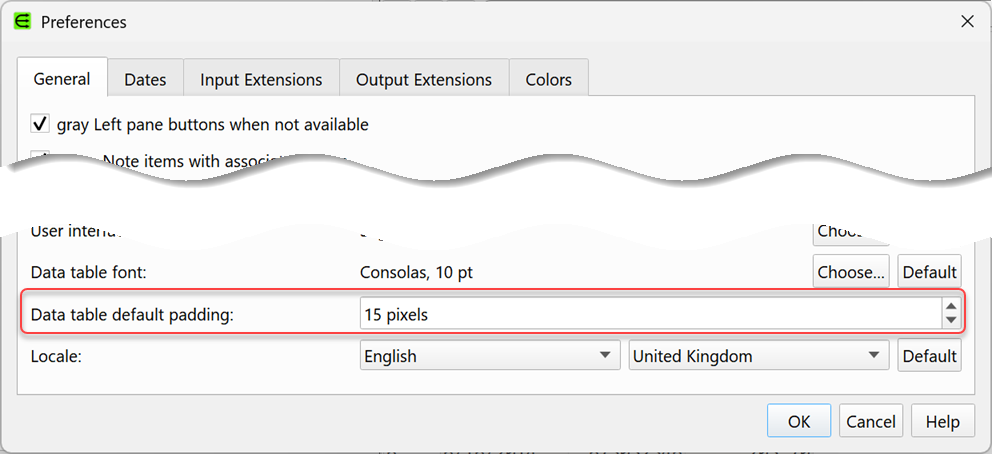
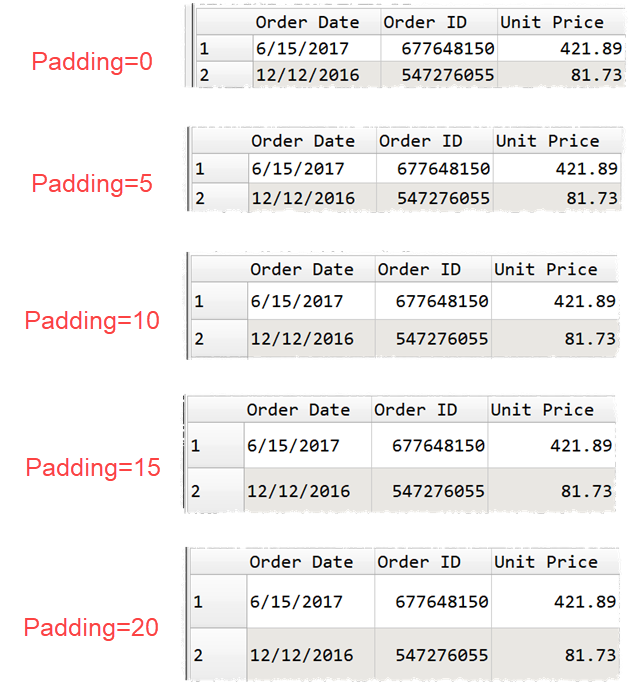
In Preferences you can now set the padding used in data tables for the default row height.
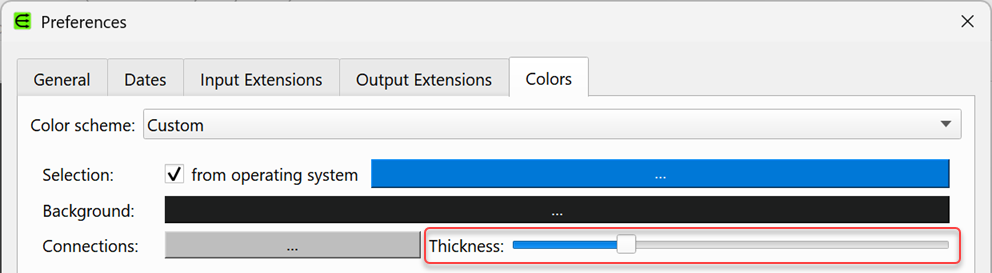
You can now vary the thickness of connections for Custom color schemes in the Colors tab of the Preferences window.
Easy Data Transform now has liquid glass compatible application icons on macOS 26.
![]()
Plus lots of minor improvements.
Advanced Edition only
Easy Data Transform Advanced Edition adds powerful visualization capabilities.
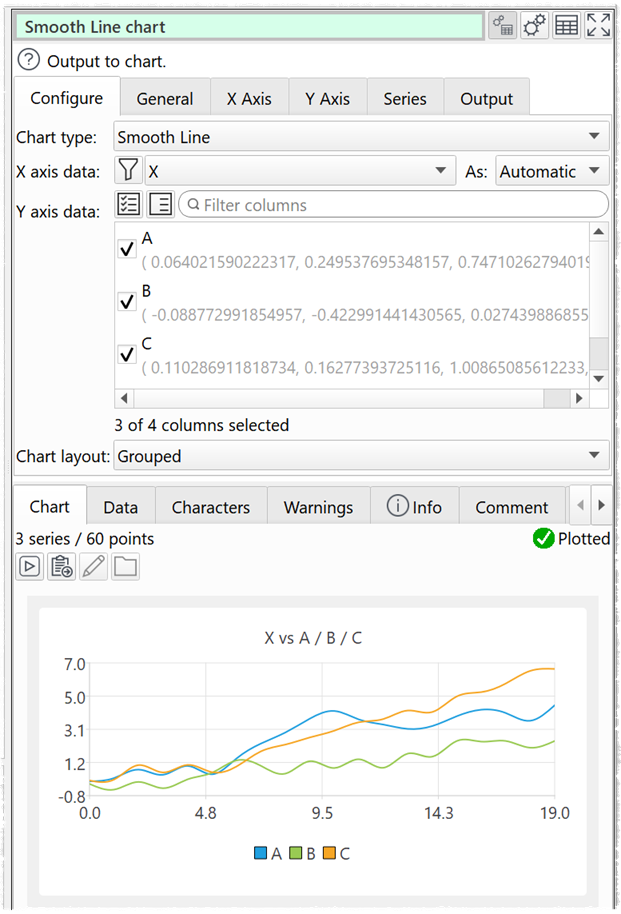
Chart types supported are:
- scatter chart
- line chart
- smoothed line chart
- area chart
- vertical bar chart
- horizontal bar chart
- pie chart
- donut chart
Here are a few examples of what you can do in just a few clicks:
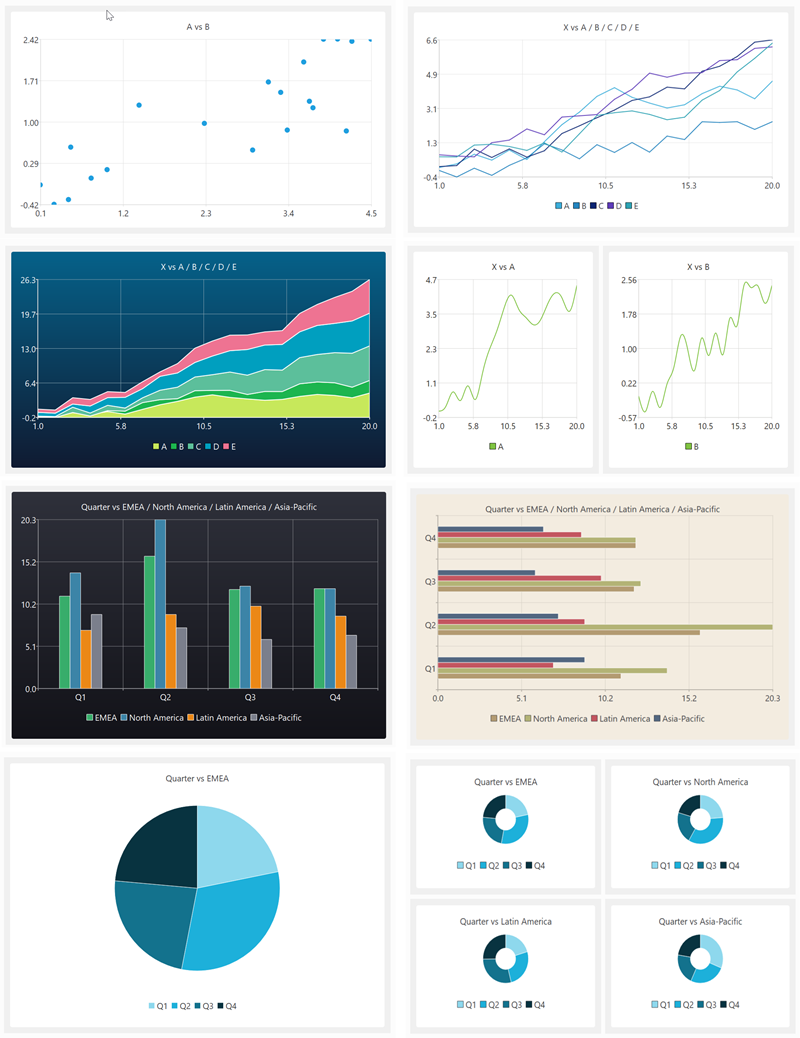
Charts can be saved to file in PNG, JPEG and PDF formats and are fully integrated into command line and batch processing.
This video gives you a quick overview of the new visualization features:

 Windows Download
Windows Download
 Mac Download
Mac Download