Easy Data Transform v1.26.0 released
Easy Data Transform v1.26.0 is now available for Windows and Mac. Improvements include:
- Fast profiling of data by value and character frequency.
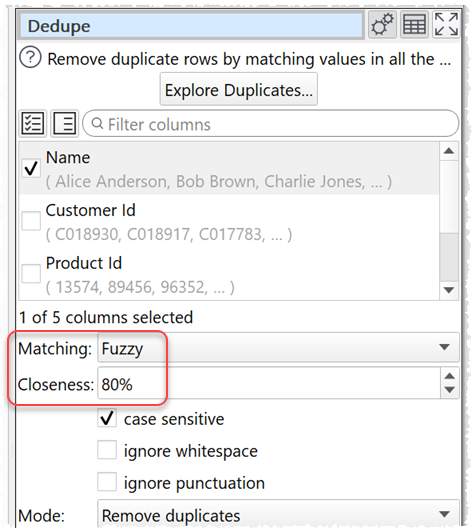
- A fuzzy match option for the Dedupe transform.
- The option to ignore spaces and punctuation in the Dedupe transform.
- A new Explore Duplicates feature for trying out and visualizing different options for the Dedupe transform.
- The option to add separator rows in the Stack and New Rows transforms.
- Additional Match Type options in the Replace transform.
- Bug fixes.
Find out more and download the new release from the release page:
This is a free upgrade for everyone with a valid license. If you don’t yet have a license, you can buy one here.
Thanks to everyone who sent us bug reports and suggestions for improvements.
Videos
We’ve been adding more videos to our YouTube channel. The latest two videos are:
You can subscribe to the channel to get notifications of new videos. It would really help us with the all-powerful YouTube algorithm if you subscribe to the channel and ‘Like’ a few videos!
Easy Data Transform YouTube channel
Fuzzy matching
Often datasets will have records that are duplicates, but are not identical. For example an address might be recorded as:
100 avenue street, townsville, ohio
And:
100 avenue st., townsville, ohio
Previously the Dedupe transform used exact matching and wouldn’t match these two addresses. But now you can use ‘fuzzy’ matching and specify the percentage difference between two records that is acceptable.
For example, doing a fuzzy match to:
100 avenue street, townsville, ohio
Gives:
| VALUE | FUZZY MATCH |
|---|---|
| 100 avenue street, townsville, ohio | 100% |
| 100 avnue street, townsville, ohio | 98% |
| 100 avenue street townsville ohio | 95% |
| 100 avenue st., townsville, ohio | 89% |
| 100 avenue st, townsville | 72% |
| 100 av. st., citysville, texas | 52% |
| townsville, ohio | 46% |
| 742 evergreen terrace, springfield, oregon | 36% |
The difference between 2 values is calculated as the number of character additions, substitutions or deletions required to turn one string into the other (the ‘Levenshtein Distance’), divided by the number of characters in the longest value.
You can now also choose to ignore whitespace and ignore punctuation in the Dedupe transform.
Note that fuzzy matching is significantly slower than exact matching. And the time taken increases with:
- the number of rows in the dataset (as approximately the square of the number of records)
- the number of columns matched
- the amount of data in each column mapped
- the closeness value (e.g. 70% is slower than 90%)
It may require a bit of experimenting to find the right value of fuzzy match. For this you can use the new Explore Duplicates feature.
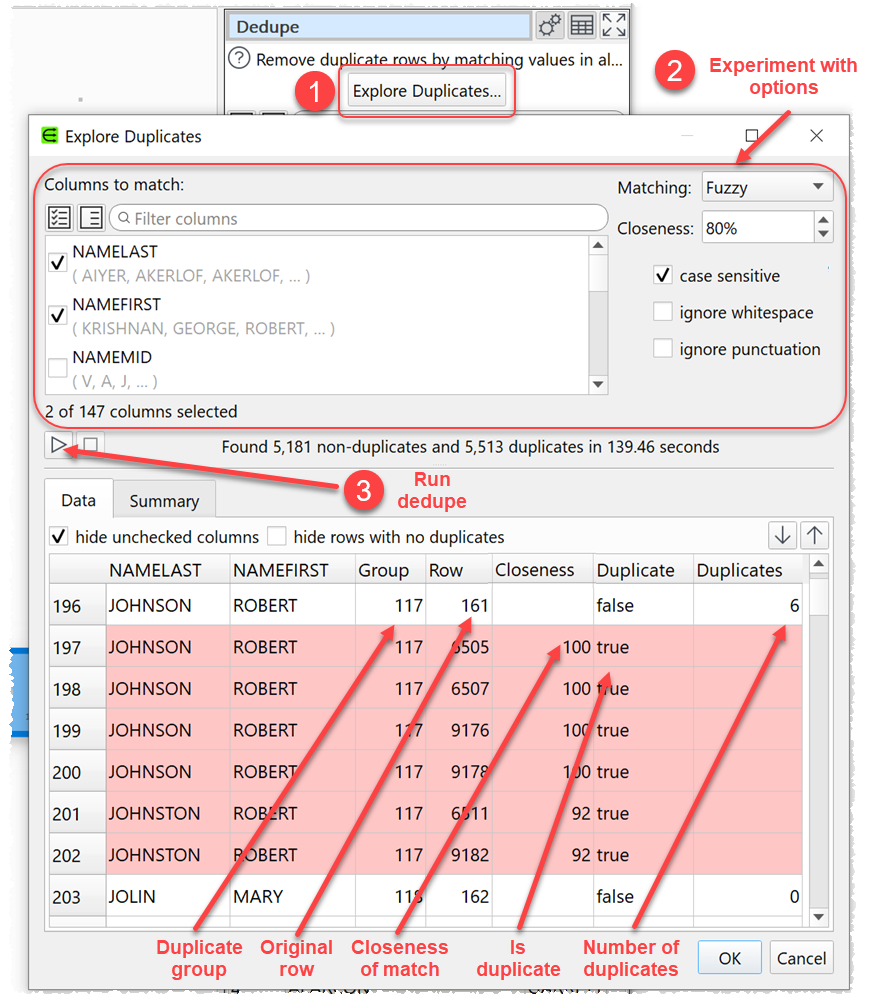
Sometimes you still need a ‘human in the loop’. In which case you can set the new Mode option to Add duplicate information, output the dataset and modify it ‘by hand’.
Dirty dirty data
Real world data is invariably ‘dirty’, with a range of issues, including: empty values, outlier values and unexpected characters. We have now improved the Column Values window so that you can get an idea of the data in each column at a glance.
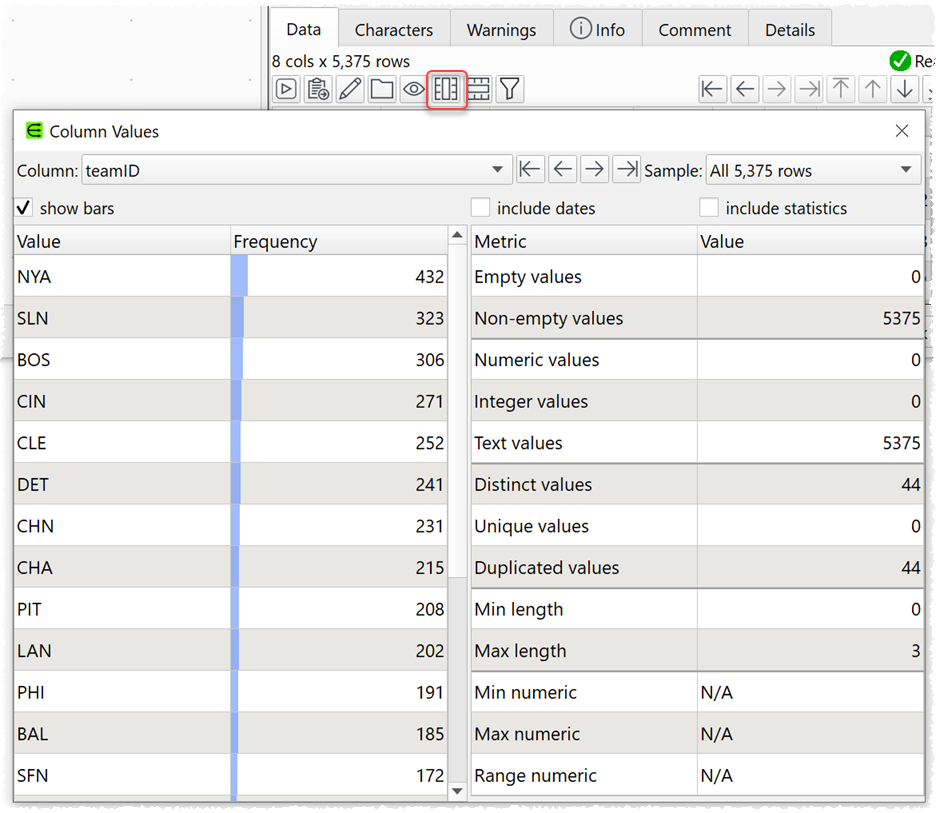
If it is a large dataset you can sample from it, for speed.
You can also identify extaneous characters in each column in the new Characters tab.
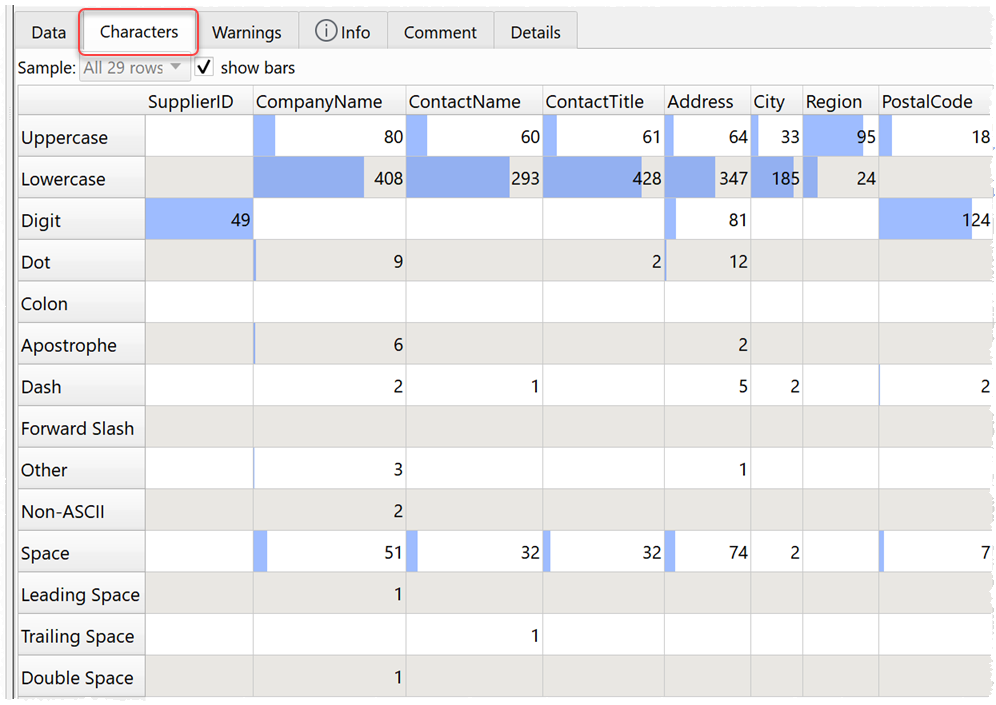
If you hover over a cell you can see up to 3 example values where that character is present.

You can use the Characters tab to give you instant feedback on changes made with the Replace and Whitespace transforms. Again you can sample large datasets, for speed.
And finally…

We have been watching the unfolding situation in Ukraine with horror. But also with huge admiration for the Ukrainians, fighting for their freedom. It is only an accident of birth that it is them, rather than us, facing down Russian tanks and artillery. If you can spare some cash, here are a couple of donation links:
https://redcross.org.ua/en/donate/
https://www.comebackalive.in.ua/
Andy Brice
Oryx Digital Ltd
17-Mar-2022